by Sam Newman, 2019 ref
Microservices are independently deployable services modelled around a business domain.
Independent deployability
This allows us to change a microservice and deploy it into production without having to utilise/change any other services. This propriety requires loose coupling ('change one service without having to change anything else'.). We use stable contracts help guide how we find the service boundaries.
Modelled around a business domain
"Any organisation that designs a system… will inevitably produce a design whose structure is a copy of the organisation's communication structure" - Melvin Conway
We used to organise people in terms of their core competence, However, changes in functionality are primarily about changes in business functionality. With this grouping (i.e. three-tier architecture with, UI team, Backend team and DBAs) the business functionality is spread across all three teams - increasing the chance that a change will cross layers and require coordination. This is an architecture in which we have high cohesion of related technology, but low cohesion of business functionality.
This does not organise people for the change we want to optimise for (business functionality), as such we now wish to group people in poly-skilled teams to reduce hand-offs and silos. Instead our business domain becomes the primary force driving our system architecture. We now have teams which manage vertical (end-to-end) slices of business functionality over horizontal slices of core competence (technology). Its up to the poly-skilled teams how the code is structured, state is stored and how it is presentated. The only external concern is the stable contract for the business functionality exposed.
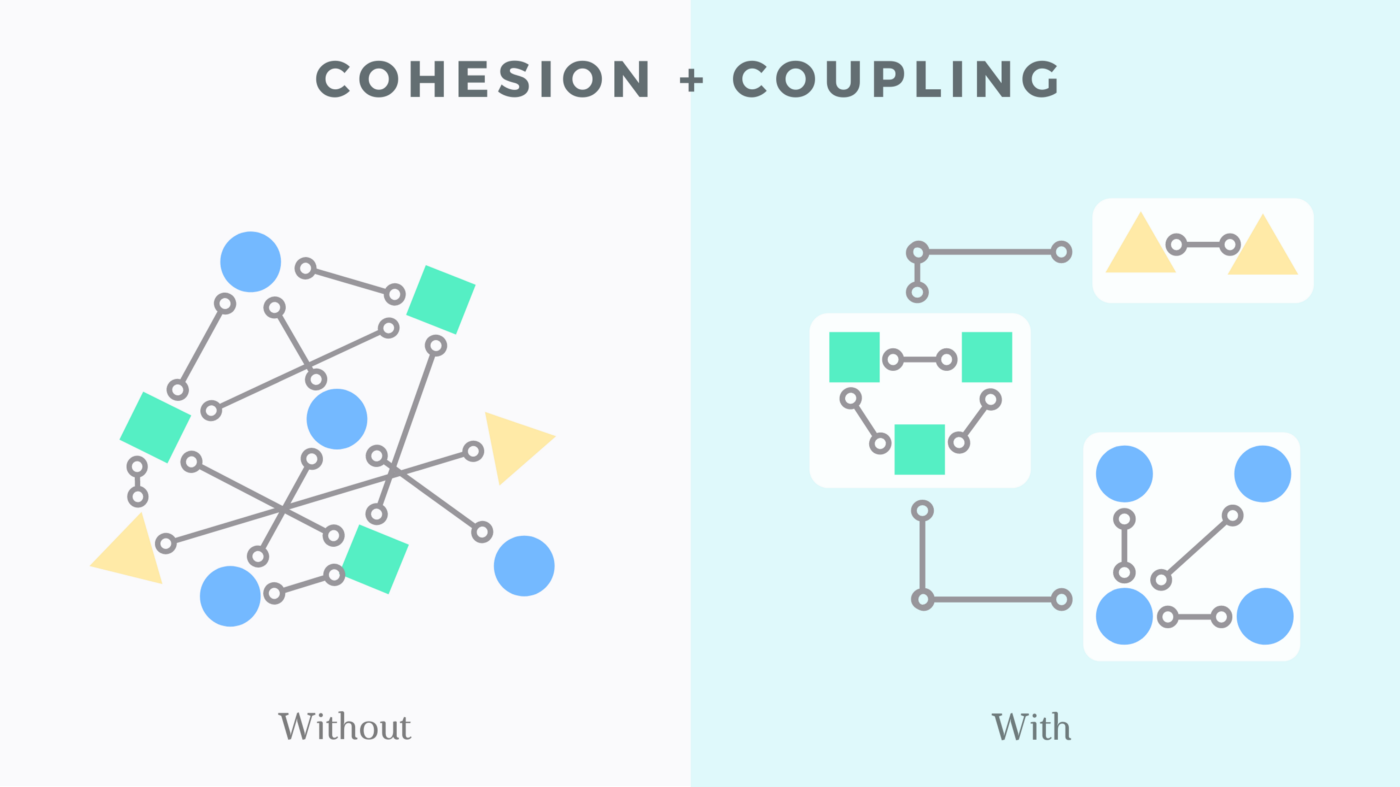
Coupling refers to the degree of interdependence between modules i.e. a change in one, requires a change in another. Desirable low coupling means that modules in a system have minimal dependence on each other.
Cohesion refers to the degree to which the elements inside a module belong together. Desirable high cohesion means that a module is focused on a single/closely related task(s) - 'the code that changes together, stays together'.
There tends to be an inverse relationship with the two forces - as cohesion increases within a module, coupling tends to decrease. The same is true the other way round, if we have two pieces of tightly related code, cohesion is low as the related functionality is spread across both. We also have tight coupling, as when this related code changes, both things need to change.
Low coupling, high cohesion is a desirable trait for reduced maintenance and modification cost of a given module.
These concepts are really important in distributed system design as getting this balance wrong has a higher cost than within a single-process monolith. We want to optimise our architecture around ease of making changes in business functionality - so we want the functionality grouped in such a way that we can make changes in as few places as possible.
Information hiding (aka. decision hiding) is an important design principle to address coupling concerns. The core idea being to separate the parts of the code that change frequently from the ones that are static. We want the module boundary to be stable, and it should hide those parts of the module implementation that we expect to change more often. The smaller the public interface of a module the less chance of coupling with other modules, as there is less for them to 'couple' with.
There a several different types of coupling to consider:
Microservices are not the goal! You should be considering migrating to a microservice architecture to achieve capabilities that your current system architecture cannot provide. The decision should be rooted in the challenges you are facing, and the changes you want to bring about.
Many organisations have achieved more effective growth and scaling than their peers by keeping groups small, fostering close bonds, and minimising bureaucracy. Models like Amazon's 'two-pizza team' and Spotify's approach support this strategy. When teams own microservices and have full control over them, they gain greater autonomy and empowerment within the larger organisation.
However you could...
Assign ownership of different parts of the codebase to various teams, such as through a modular monolith approach. This could also be done by empowering individual team members to make decisions based on their expertise in specific areas of the codebase (e.g., X specialises in display ads, while Y has extensive knowledge of the checkout flow).
By making and deploying changes to individual microservices independently, without waiting for coordinated releases, we can deliver new functionality to our customers more quickly.
However you could...
Numerous factors affect the speed of software delivery. It is recommended to conduct a path-to-production modelling exercise, as it could reveal that the primary obstacle isn't what you anticipate.
Dividing our processing into individual microservices allows for independent scaling of each process. This approach potentially enables cost-effective scaling, focusing resources on scaling only the parts of our processing that currently limit our ability to handle loads. Additionally, we can scale down or deactivate microservices experiencing lower loads, optimising resource usage as needed.
However you could...
Scale vertically and just get a bigger box for a quick, short-term improvement. Another option to explore is horizontal scaling of the existing monolith, which is a relatively simple step to take and should be considered before investigating microservices for this purpose.
Segmenting our application into independently deployable processes offers various mechanisms to enhance the resilience of our applications. With this approach, an issue in one area of functionality doesn't necessarily affect the entire system. We can prioritise our efforts on the parts of the application requiring the most robustness. Microservices don't inherently guarantee robustness; however, they provide opportunities to design a system that can better withstand network partitions, service outages, and similar challenges.
Robustness refers to a system's capacity to respond to anticipated variations, while resilience involves an organisation's capability to adapt to unforeseen circumstances. For instance, anticipating a potential machine failure, we enhance system robustness by introducing redundancy through load balancing. Resilience, however, encompasses the organisational process of preparing for unforeseeable challenges, acknowledging that not all potential problems can be predicted.
However you could...
Deploy multiple copies of the monolith, possibly behind a load balancer or another load distribution mechanism such as a queue. In doing so we introduce redundancy to our system - improving robustness.
In 'The Mythical Man-Month', Frederick Brooks argues that adding more people to a project can improve delivery only if the work can be divided into distinct tasks with minimal interdependencies. He illustrates this concept with the analogy of harvesting crops: multiple harvesters can work simultaneously in a field because their tasks don't require constant interaction. However, software development differs in that tasks vary, and outputs from one task often serve as inputs for others.
By establishing clear boundaries and designing an architecture that minimises interdependencies between microservices, we create functionality that can be developed independently with a low degree of coupling. This approach aims to increase developer scalability by reducing delivery contention.
However you could...
An alternative approach could be to consider implementing a modular monolith: where-by different teams own each module, and as long as the interface with other modules remains stable, they could continue to make changes in isolation.
Monoliths typically constrain our technological options, binding us to a single programming language, deployment platform, operating system, and database. Conversely, a microservice architecture offers the flexibility to diversify these choices for each service. By confining technological changes within individual service boundaries, we can evaluate the benefits of new technologies in isolation and mitigate the impact if issues arise.
Mature microservice organisations often restrict the number of technology stacks they support. However, the ability to experiment with new technologies safely can provide them with a competitive edge, both in terms of delivering superior results for customers and in fostering developer satisfaction as they gain expertise in new skills.
However you could...
We could easily embrace new languages within the same runtime environment; for instance, the JVM can seamlessly accommodate code written in multiple languages within a single running process. However, integrating new types of databases poses greater challenges, as it often requires decomposing a previously monolithic data model to facilitate an incremental migration.
Incorrectly defining service boundaries can result in significant costs. It may necessitate a higher frequency of cross-service modification, create overly interdependent components, and, overall, prove to be more detrimental than maintaining a single monolithic system.
Decomposing a system into microservices prematurely can incur significant costs, particularly for those unfamiliar with the domain. It's generally easier to transition an existing codebase into microservices than to start with microservices from scratch.
Microservices are particularly beneficial for startups transitioning into scale-ups, tackling challenges that arise post-initial success. It's easier to partition an existing brownfield system than to do so upfront with a new greenfield system. Focus on success initially, splitting only around clear boundaries and maintaining a more monolithic approach for the rest. Startups often experiment with various ideas to find a fit with customers, which can result in significant shifts in the product domain (an unclear domain, as above).
If your software is packaged and shipped to customers for self-operation, microservices might not be the most suitable option. Adopting a microservice architecture shifts significant complexity to the operational domain. It's unrealistic to assume that customers will possess the necessary skills or platforms to manage microservice architectures.
The primary reason to avoid adopting microservices is the lack of a clear understanding of your objectives. Simply following the trend without a solid purpose is unwise and can lead to unfavourable outcomes.
Making reuse a primary objective for microservice migration is often considered a misstep. It's not a direct outcome that people desire; rather, it's something they hope will lead to other benefits. While we anticipate that reuse may accelerate feature delivery or reduce costs, it's essential to monitor these primary objectives directly rather than fixating solely on reuse. Otherwise, there's a risk of optimising the wrong aspect of the development process.
"If you do a big-bang rewrite, the only thing you’re guaranteed of is a big bang" - Martin Fowler
It's recommended to gradually dismantle monoliths, extracting them bit-by-bit. An incremental approach allows for learning about microservices iteratively. Attempting a complete overhaul at once can hinder effective feedback on what's working well or not. Embrace the likelihood of making mistakes and focus on minimising their impact.
Each step provides valuable insights. Start with small areas of functionality, implement them as microservices, deploy them into production, and assess their effectiveness. It's crucial to understand that the extraction of a microservice isn't finalised until it's actively utilised in production.
"Some decisions are consequential and irreversible or nearly irreversible - one-way doors - and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don’t like what you see on the other side, you can’t get back to where you were before. We can call these Type 1 decisions. But most decisions aren’t like that - they are changeable, reversible—they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups." - Jeff Bezos
Mistakes are inevitable and should be embraced, but it's crucial to understand how to minimize their costs. The terms 'Type 1' and 'Type 2' may not be descriptive enough, so using 'Irreversible' for Type 1 and 'Reversible' for Type 2 can provide clarity. Viewing Irreversible and Reversible decisions as two ends of a spectrum helps gauge their impact on potential course corrections. Planning often takes place on the whiteboard, where the cost of change and mistakes is minimal. Sketching out the proposed design and testing various use cases across potential service boundaries can provide valuable insights. When it comes to decomposing an existing monolithic system, we need to have some form of logical decomposition to work with, and this is where domain-driven design can come in handy.
Bounded contexts are excellent starting points for defining microservice boundaries. A domain model provides a logical view of an existing system, but there is no guarantee that the underlying existing code structure aligns with this model. Additionally, a domain model won't indicate which bounded contexts store data in a given database for example. Despite this, developing a domain model is crucial for structuring a microservice transition. It's important to gather just enough information from the domain model to make informed decisions about where to begin the decomposition.
For example, Invoicing might seem like an easy initial step, if our aim is to enhance time to market and the Invoicing feature seldom undergoes changes, it might not be the most productive use of our time.
We seek quick wins for early progress, momentum, and feedback, which leads us to choose easier components to extract. However, we also need to ensure that the decomposition provides meaningful benefits. Balancing these considerations is crucial in our decision-making process.
Event Storming, created by Alberto Brandolini, is a collaborative exercise where technical and non-technical stakeholders come together to define a shared domain model. This process starts from the bottom up, with participants identifying 'Domain Events' - things that happen in the system. These events are then grouped into aggregates, which are subsequently organised into bounded contexts. The goal of Event Storming is to understand the logical events occurring in the system, rather than to build an event-driven system. The value lies not only in the model itself but also in the shared understanding developed through this collective exercise.
Aligning architecture and organisation can be pivotal in maximising the benefits of a microservice architecture. Traditionally, IT organisations were structured based on core competencies, with backend/frontend developers, testers, and DBAs each forming separate teams. This setup often led to multiple hand-offs between teams during software development and deployment, resulting in delays. Similarly, organisational silos could impede efficiency, as involving multiple teams in software creation or changes could prolong the process.
These silos have been breaking down. Rather than concentrating on specific technologies or activities, teams focus is now on different aspects of the product, mirroring the shift from technical-oriented services to services organised around vertical slices of business functionality.
The DevOps movement has prompted many organisations to move away from centralised operations teams, empowering delivery teams with greater responsibility for operational considerations. The roles of centralised teams have evolved significantly. Previously focused on executing tasks themselves, these teams now primarily support and enable delivery teams. This support may involve embedding specialists within teams, developing self-service tooling or providing training. Their responsibility has transitioned from execution to facilitation, fostering the emergence of more independent and autonomous delivery teams.
But remember! Draw inspiration from the experiences of other organisations, but avoid assuming that their solutions will seamlessly apply to your context. As Jessica Kerr stated regarding the Spotify model (from the well known 'Scaling Agile' paper), focus on replicating the underlying questions rather than blindly adopting their answers. Ensure that any changes you implement are grounded in a deep understanding of your company, its requirements, its personnel, and its cultural nuances.
The Sunk Cost Fallacy, also termed the Concorde Fallacy, refers to the tendency for individuals to continue investing resources (time, money, effort) into a project or decision, even if it's clear that the expected outcome is unlikely to justify the additional investment. This behaviour occurs because people focus on the resources already invested ('sunk costs') rather than objectively assessing the future benefits and costs of continuing or discontinuing the endeavour.
Breaking down tasks into smaller steps helps mitigate the sunk cost fallacy and facilitates easier course adjustments. Utilising the checkpoint mechanism enables reflection on progress. While it's not necessary to change direction immediately at the first sign of trouble, disregarding evidence of success or failure is riskier than not gathering evidence at all.
We want to transition to a microservice architecture incrementally, allowing us to learn and adapt as needed, without a complete rewrite. To do this, we have to ensure that we can continue to work with, and make use of our existing monolithic applications. If we can modify the current system, it offers the most flexibility. However, constraints like lack of source code, obsolete technology skills, or high modification costs might limit this. Additionally, the monolith could be in poor condition or heavily used by others, complicating changes.
When migrating functionality to new microservices, it's not always clear what to do with the existing code. Should we move the code as is or re-implement the functionality? If the monolithic codebase is well-structured, moving the code itself can save significant time.
Experience has shown that the biggest barrier to using existing monolithic code in new microservices is that monolithic codebases are typically not organised around business domain concepts. Instead, they are categorised technically (e.g. Model, View, Controller). This makes it challenging to move business domain functionality, as it can be difficult to locate the code to move.
In the book 'Working Effectively with Legacy Code' Michael Feathers defines a seam as a place where you can change a program's behaviour without editing the existing behaviour. Essentially, you define a seam around the code you want to change, develop a new implementation, and then swap it in. While Michael’s concept of seams can be applied broadly, it fits particularly well with bounded contexts.
After understanding the existing codebase, you could consider extracting the newly identified seams as separate modules to create a modular monolith. This approach allows for independent module development, providing many benefits while avoiding many of the challenges of a microservice architecture.
In practice it is found that few teams refactor their monoliths before transitioning to microservices. More commonly, teams identify the responsibilities of the new microservice and create a clean-room implementation of that functionality. This approach risks the problems of big bang rewrites. To avoid this, rewrite only small pieces of functionality at a time and regularly deliver the updates to customers. If reimplementing the service takes a few days or weeks, it's manageable. But if it starts taking several months, it's time to reassess the approach.
One widely-used technique for system rewrites is known as the strangler fig application. Inspired by a type of fig tree that starts growing on a host tree's upper branches and gradually replaces it, this approach in software involves the new system initially wrapping around and relying on the existing one. Over time, the new system can grow independently until it completely supplants the old one. This method supports incremental migration to a new system, allowing for pauses in the process while still utilising the progress made so far. Each step in this approach is designed to be reversible, minimising the risks associated with incremental changes.
The pattern is comprised of three steps:
Note: until the call to the moved functionality is redirected, the new functionality isn’t technically live, even if it is deployed into a production environment.
Separating deployment from release is important as it allows validation in the production environment before customer use, minimising rollout risks.
Allowing changes to functionality during the migration complicates potential rollbacks. It's simpler to avoid changes until migration is fully complete. The longer the migration process, the more challenging it becomes to enforce a 'feature freeze' in that system area though. Smaller migrations reduce the urgency to modify functionality before completing the process.
The user interface offers valuable opportunities to integrate functionality from both the existing monolith and new microservices. UI composition effectively facilitates system re-platforming by enabling migration of complete vertical slices of functionality. It does however require the ability to modify the existing user interface to incorporate said functionality. This can be done achieved using:
For the strangler fig pattern to be effective, we need to intercept calls at the perimeter of our monolith. However, if the functionality we aim to extract is deep within the existing system, significant changes are necessary. These changes can disrupt other developers working concurrently on the codebase. To balance these tensions, developers typically work on separate source code branches when reworking parts of the codebase. This approach minimises disruption but introduces challenges when merging changes back into the main branch. The branch by abstraction pattern offers an alternative by modifying the existing codebase to safely integrate new implementations alongside existing ones in the same version, reducing disruption to other developers while allowing for incremental changes.
Branch by abstraction consists of five steps:
There is a variation of this pattern called verify branch by abstraction, where-by if calls to the new implementation fail, then the system is able to automatically fallback to the old implementation.
This approach enables triggering new behaviour within the monolith without changing it, using the decorator pattern to simulate direct calls from the monolith to our services. Instead of intercepting calls, we let them proceed normally and then call external microservices based on the results through mechanisms like proxies. This pattern works best when necessary information can be extracted from the inbound request or the monolith's response, but becomes complex when additional information is needed for the new service. Such as requiring to fetch more information from the monolith to complete the microservices action.
With change data capture, rather than trying to intercept and act on calls made into the monolith, we react to changes made in a datastore. For change data capture to work, the underlying capture system has to be coupled to the monolith’s datastore. There are several ways of reacting to these changes within your microservices:
This approach is suited when you need to react to data changes in the monolith but cannot intercept these changes at the system's perimeter (strangler or decorator) or modify the underlying codebase.
Microservices work best when we practice information hiding, which means having their own data store. With a shared database it can be unclear as to who 'controls' the data and where the business logic that manipulates this data resides.
Shared databases are considered appropriate within a microservice architecture only for:
To provide a single source of data for multiple services while mitigating coupling concerns, a read-only view can be used. This view presents a service with a limited projection from the underlying schema, implementing a form of information hiding. Database views should be maintained by the team managing the source schema, similar to other service interfaces. This approach is limited to query results and requires services to have access to the source database.
The database wrapping service pattern hides the database behind a thin service wrapper, converting database dependencies into service dependencies. This allows control over what is shared and hidden, which is useful when the underlying schema is too complex to separate. By enforcing access only through the wrapping service, further growth of the database can be controlled and ownership boundaries clarified. Unlike simple database views, this pattern allows for more sophisticated data projections and supports write operations via API calls. However, it does require consumers to switch from direct database access to using the API.
Sometimes, clients need a database to query for large data sets because their tools require a SQL endpoint. For this we can create a dedicated, read-only database that is updated whenever the underlying database changes. This is similar to exposing a stream of events or a synchronous API. An mapping engine is used as an abstraction layer between internal and external databases, ensuring the public-facing database remains consistent even if the internal database structure changes.
Microservices should be viewed as a combination of behaviour and state, similar to aggregates. When exposing an aggregate from the monolith, the monolith retains control over permitted state changes, acting as more than just a database wrapper. This approach involves exposing operations that let external parties query the current state of an aggregate and request new state transitions. We can restrict which aspects of an aggregate's state are exposed and limit which state transition operations can be requested externally.
When the data is still 'owned' by the monolith, this pattern effectively provides your new services with the necessary access. For extracted services, having the new service call back to the monolith for data access is usually not much more work than directly accessing the monolith's database, but it is a better long-term solution (over Database Views, for example).
If the microservice has assumed responsibility for that behaviour or data, we should invert the dependency, making the monolith treat the new service as the source of truth. This means the monolith will call the microservice's endpoint to read data and request changes.
The strangler fig pattern offers the flexibility to revert back to the monolith if issues arise after transitioning to the new service. However, challenges can occur when the new service must maintain data synchronisation with the monolith.
This approach ensures database synchronisation through code, with either the monolith or the new service handling writes to both databases. It works best when either the new service or the monolith exclusively manages writes at any given time, which is conducive to a straightforward switchover strategy like the strangler fig pattern. However, during scenarios like canary deployments where requests might interact with both the monolith and the new service concurrently, maintaining synchronisation becomes complex, making this pattern less suitable.
With the Tracer write pattern, the data's source of truth is gradually shifted, allowing for coexistence of two sources during migration. A new service is chosen to host the relocated data, while the current system maintains a local record. Updates are synchronised by ensuring changes are mirrored to both the current system and the new service through its service interface. Existing code is then adapted to exclusively utilise the new service. Once all functionality relies on the new service as the primary source, the old source can be phased out.
A transaction is a sequence of operations performed as a single, indivisible unit of work. Transactions ensure that all operations succeed or none do, maintaining integrity and consistency, which simplifies system development and maintenance.
Typically, when we talk about database transactions, we talk about ACID transactions.
When we split our database apart we can still use ACID transactions, however, the scope of these transactions is reduced to a specific service - not across services.
The two-phase commit (2PC) algorithm is used for transactional changes in distributed systems, involving two phases: voting and commit. During the voting phase, a coordinator checks if all workers can perform a state change. If any worker cannot, the operation aborts. If all agree, the commit phase begins, and changes are made.
There are several limitations to this approach:
This means of distributed transaction should be avoided when coordinating state changes across microservices due to complexity and above limitations. If possible, avoid splitting data that requires atomic and consistent management. Keep such data in a single database and manage it within a single service or monolith. If data must be separated across services look to the below Saga pattern instead.
Unlike a two-phase commit, a saga coordinates multiple state changes without long-term resource locking. It achieves this by modelling steps as independent activities, promoting explicit business process modelling. Originally proposed for long-lived transactions (LLTs), sagas split LLTs into shorter, independent (ACID) transactions to minimize database contention. This approach extends to coordinating changes across multiple services, breaking down business processes into sequential calls within a single saga. It's crucial to note that while sagas lack the atomicity of traditional ACID transactions across the entire saga, each sub-transaction maintains ACID properties individually, enabling reasoned state management.
In sagas, handling failures involves two recovery approaches: backward recovery and forward recovery. Backward recovery reverts failures through compensating actions that undo committed transactions. Forward recovery retries transactions from the failure point, ensuring that the entire saga progresses towards completion despite encountering possible transient failures.
It's practical to employ varied failure recovery approaches. Certain failures may necessitate rollback (backward recovery), while others can proceed forward (forward recovery). For example: In the context of order processing, after receiving payment and packaging the item, the final step is dispatching. If dispatch fails due to operational reasons, like a lack of delivery capacity, rolling back the entire order seems unnecessary. Instead, retrying the dispatch and involving human intervention if retries fail is a more logical approach to resolve the issue.
Orchestrated sagas employ a central coordinator, or orchestrator, to dictate the sequence of operations and trigger compensating actions when needed (similar to a musical conductor). This command-and-control approach provides clear visibility into saga execution. Explicitly modelling business processes within the orchestrator enhances system understanding and facilitates onboarding. However, this approach increases domain coupling, as the orchestrator must be aware of all involved services. It also risks centralising logic that should ideally reside within individual services, potentially leading to service anemia. To mitigate these issues, consider distributing orchestration responsibilities among different services for different workflows, promoting service autonomy and reuse of functionality across various business processes.
Choreographed sagas distribute responsibility among multiple collaborating services, contrasting with the command-and-control nature of orchestrated sagas. It is analogous to a dance, where-by everyone knows what they need to do - communicating and moving with each other, there is no single conductor telling them what to do. Services communicate through events broadcasted throughout the system, where each service reacts autonomously to events it receives without direct knowledge of other services. This decentralised approach reduces coupling and avoids centralised logic. However, understanding the overall business process becomes challenging without an explicit model. Additionally, tracking saga state for necessary actions like compensating transactions becomes complex without a central coordinator. To address this, systems can use correlation IDs in events, allowing a dedicated service to track saga states and manage necessary actions programmatically.
Don’t think of adopting microservices as flipping a switch; think about it as turning a dial. As you increase your use of microservices, you'll unlock their benefits but also encounter new challenges. Addressing these requires fresh thinking, new skills, different techniques, and possibly new technology.
Strong code ownership
Every service has designated owners. Changes by non-owners must be submitted to the owners for approval. Using pull requests is one way to manage this process.
Strong code ownership is common in large-scale microservice architectures with multiple teams and over 100 developers. This model promotes product-oriented teams, allowing them to focus on specific business domains. Such teams maintain customer focus, build domain expertise, and often work with embedded product owners.
Weak code ownership
Most services have designated owners, but anyone can still make direct changes. Source control allows open access, with the expectation that changes to others' services are discussed with the owners beforehand.
Collective code ownership
No one owns anything, and anyone can change anything they want. For collective ownership to work, the team must be well-connected and share a common understanding of good changes and the technical direction for each service.
For small teams, collective code ownership works well. However, for rapidly growing teams, it becomes problematic. Collective ownership requires time for consensus to form and evolve, which is difficult with increasing team size and rapid hiring.
A microservice is part of a larger system, consuming and/or exposing functionality. We aim for independent deployability, ensuring changes don't break consumers, with this exposed functionality acting as a contract.
Eliminate accidental breaking changes
An explicit schema for your microservice helps detect structural breakages. For example, changing a method from taking two integers to one is an obvious breaking change. Semantic breakages can also occur however; if a method that added two integers now multiplies them, it breaks the contract (expected behaviour) as well. Make contract changes obvious to developers with explicit schemas and thorough test coverage.
Think twice before making a breaking change
Prefer expanding your contract by adding new methods or resources without removing the old ones. Support both old and new functionality whenever possible. This provides you with a means of you and your consumers gracefully moving over to the revised contract behaviour.
Give consumers time to migrate
Microservices should be independently deployable. Changes must not impact existing consumers, allowing them to use the old contract while the new one is available. Give consumers time to migrate to the new version by either running two versions side-by-side or, preferably, supporting both contracts within a single version.
In a monolithic system, a single database makes data analysis straightforward with a ready-made schema for reporting. Microservice architecture scatters data across isolated schemas, complicating these efforts. Stakeholders often rely on tools and processes that require direct SQL access to a single database, usually tied to the schema design of your monolithic database. To avoid disrupting their workflow, you may need to present a single database for reporting, potentially matching the old schema to minimize changes. If your monolith uses a dedicated data source like a data warehouse or data lake, ensure microservices copy data there to maintain reporting.
“We replaced our monolith with microservices so that every outage could be more like a murder mystery.” Honest Status Page (@honest_update)
Monitoring a monolithic application is straightforward: with fewer machines and a binary failure mode, the system is either up or down. High CPU usage (e.g. 100%) clearly indicates a problem. In contrast, a microservice architecture involves numerous services and instances, where a single service failure doesn't necessarily mean the whole system is down. Therefore, the level of importance of a 100% CPU could be deemed a lower severity in this case.
Log aggregation
With a few long-lived machines, logs could be fetched directly from the machines. However, in a microservice architecture with many more, often short-lived processes, a log aggregation system is essential. It captures and forwards all logs to a central location for searching and alert generation.
Tracing
Analysing call sequences and identifying the source of failures or latency spikes in microservices is challenging when viewing each service in isolation. Collating these flows is invaluable, this can be achieved by generating correlation IDs for all incoming calls and tying the different service requests together using it. Along with logs, we can also trace the time taken for calls etc. using distributed tracing tools like Jaeger.
Testing in production
Functional automated tests provide feedback on software quality before deployment, but we need ongoing feedback in production. New deployments or environmental changes can break features that previously worked. By using synthetic transactions to simulate user behaviour, we can define expected outcomes and set up alerts for failures. Start by adapting existing end-to-end test cases for production use, ensuring these tests don't adversely impact the production environment.
Observability
Traditional monitoring and alerting focus on predicting known issues, like disk-space running out, unresponsive services, or latency spikes. However, as systems become more complex, it's harder to foresee all potential problems. Therefore, it's crucial to enable open-ended inquiries into our systems when issues arise, to quickly stabilize operations and gather data for future fixes. Comprehensive data collection, including tracing and logs, allows us to investigate unexpected problems using real information rather than conjecture.
As the number of services grows, the developer experience can deteriorate. Resource-intensive runtimes like the JVM limit the number of microservices that can run on a single machine, slowing down local builds and execution. Developers may request more powerful machines, but this is only a temporary fix if services continue to grow. Teams practicing collective ownership of multiple services are more affected, as they often need to switch between services. In contrast, teams with strong ownership of fewer services focus on their own and develop methods to stub out external services.
To reduce the number of locally run services, developers commonly stub out unnecessary services or point to instances running elsewhere. A fully remote setup can leverage more capable infrastructure for numerous services. Monitoring how the developer experience evolves with increasing services is crucial. Implement feedback mechanisms and invest continuously to maintain developer productivity.
As the number of services and instances grows, managing deployments and configurations becomes more complex. Traditional methods for handling monolithic applications often don't scale well with numerous microservices. Desired state management becomes crucial. This involves specifying and maintaining the required number and location of service instances. Manual processes might work for monoliths but won't scale with tens or hundreds of microservices, each with different desired states. This is when you should look into tooling such as Kubernetes or follow a Serverless-first mindset and go with FaaS offerings such as AWS Lambda.
When employing automated functional tests, there's a delicate balance to maintain. The broader the functionality tested, the greater the confidence in your application, but this also increases test duration and complexity in diagnosing failures. In a microservice architecture, end-to-end tests span multiple services, requiring deployment and configuration across these services, and encountering challenges like false negatives due to environmental issues.
To manage this effectively:
Embracing decentralised decision-making within teams, including full lifecycle ownership of microservices, necessitates balancing local autonomy with global alignment. A common challenge arises when multiple teams independently address the same issue without realising it, leading to inefficiencies over time.
This issue typically surfaces in multi-team organisations, particularly those granting teams greater autonomy. It often becomes apparent after periods of rapid scaling, where increased developer numbers strain ad hoc information sharing, fostering information silos. Collective ownership of services can mitigate these challenges by promoting consistent problem-solving approaches.
Ultimately, this challenge revolves around distinguishing between reversible and irreversible decisions. Decisions with higher change costs require broader consensus. Teams must recognise when decisions lean towards irreversibility and involve stakeholders outside their team to ensure effective collective ownership and scalability.
In distributed systems, failure modes such as lost network packets, timeouts, and machine failures are common, contrasting with the relative simplicity of monolithic setups. These challenges are most pronounced in production environments, where replicating these conditions during testing is challenging. As the number of services and service calls grows, systems face heightened vulnerability to resilience issues like cascading failures and back pressure, particularly in tightly interconnected environments.
Potential Solutions
Resilience goes beyond pattern implementation; it involves cultivating an organisational culture prepared to address unforeseen challenges and adapt practices as needed. A practical step is documenting production issues promptly and learning from them.
Organisations struggle with fundamental challenges in asset management, often uncertain about what they possess, its location, and responsible oversight. Microservices, when highly specialised, can persist without updates for long durations, leading to 'orphaned services' lacking active ownership. Addressing this requires implementing collective ownership practices, fostering shared responsibility among teams and utilising collaborative tools for effective service management.